

Exclusive - Source Code Spoofing with HTML5 and the LRO Character
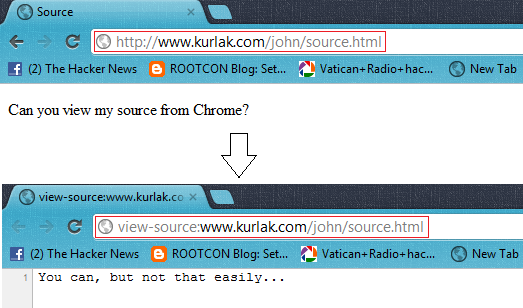

Article Written by John Kurlak for The Hacker News,He is senior studying Computer Science at Virginia Tech. Today John will teach us that How to Spoof the Source Code of a web page. For example, Open http://www.kurlak.com/john/source.html and Try to View Source Code of the Page ;-) Can you View ??
About eight months ago, I learned about HTML5’s new JavaScript feature, history.replaceState(). The history.replaceState() function allows a site developer to modify the URL of the current history entry without refreshing the page. For example, I could use the history.replaceState() function to change the URL of my page in the address bar from “http://www.kurlak.com/example.html” to “http://www.kurlak.com/example2.html” When I first learned of the history.replaceState() function, I was both skeptical and curious.
First, I wanted to see if history.replaceState() supported changing the entire URL of a page, including the hostname. Fortunately, the developers were smart enough to prevent that kind of action. Next, I noticed that if I viewed the source code of a page after replacing the URL, it attempted to show the source code of the new page. I started brainstorming ways I could make the URL look the same but have a different underlying representation. Such a scenario would make it so that I could “hide” the source code of a page by masking it with another page. I remembered encountering a special Unicode character some time back that reversed all text that came after it. That character is called the “right to left override” (RLO) and can be produced with decimal code 8238.
I tried to create an HTML page, “source.html,” that would use history.replaceState() to replace the URL of the page with: [RLO] + “lmth.ecruos” (the reversed text of “source.html”). When the browser rendered the new URL, the RLO character reversed the letters after it, making the browser display “source.html” in the address bar. However, when I went to view the source of the web page, my browser tried to view the source of “‮lmth.ecruos” instead (the characters, “‮,” are the ASCII representation of the hex codes used to represent the RLO character). Thus, I created a page, “‮lmth.ecruos” and put some “fake” source code inside. Now, when I went to “source.html,” the URL was replaced with one that rendered the same, and when I viewed the source of the page, it showed my “fake” source code.
The code I used for “source.html” was:

However, there was a downfall: if the user tried to type after the RLO character in the address bar, his or her text would show up backwards, a clear indication that something strange was going on. I brainstormed additional solutions. I soon found that there was also a “left to right override” (LRO) character. I discovered that placing the LRO character within text that is already oriented left to right does not do anything. I decided to add the LRO character to the end of my URL and used the following code:
 Then, I simply had to create “source.html— and put my “fake” source code in it. It worked! Now the user could type normally without seeing anything funny.
Then, I simply had to create “source.html— and put my “fake” source code in it. It worked! Now the user could type normally without seeing anything funny.However, this new code still has two downfalls.
The first downfall is that the script appears to work only for Google Chrome (I tested the script in Chrome 17.0.963.79 m). Firefox 11 escapes the RLO character, so the user sees “%E2%80%AElmth.ecruos” in the URL bar instead of “source.html.” (I have had reports, however, that the “exploit” works in Firefox 11 on Linux. I have not yet confirmed those reports). Internet Explorer 9 does not yet support history.replaceState(), but apparently Internet Explore 10 will. Opera 11 and Safari 5 both show “source.html” in the address bar, but when I go to view the page source, both browsers bring up the code for the original “source.html.”
The first downfall is that the script appears to work only for Google Chrome (I tested the script in Chrome 17.0.963.79 m). Firefox 11 escapes the RLO character, so the user sees “%E2%80%AElmth.ecruos” in the URL bar instead of “source.html.” (I have had reports, however, that the “exploit” works in Firefox 11 on Linux. I have not yet confirmed those reports). Internet Explorer 9 does not yet support history.replaceState(), but apparently Internet Explore 10 will. Opera 11 and Safari 5 both show “source.html” in the address bar, but when I go to view the page source, both browsers bring up the code for the original “source.html.”
The second downfall is that if the user tries to refresh the page, he or she will be taken to the fake HTML page. As far as I know, there is no sure way to prevent this side effect.
Finally, I would like to point out that this “exploit” is just a cool trick. It cannot be used to prevent someone from retrieving the source code of a web page. If a browser can access a page’s source code, a human can access that page’s source code.
Maybe someone else can think of a more interesting use of the trick. I hope you like it!
Submitted By : John Kurlak
Website: http://www.kurlak.com
Found this article interesting? Follow us on Google News, Twitter and LinkedIn to read more exclusive content we post.





























